

[String, StringBuffer 그리고 StringBuilder의 차이를 알아야 하는 이유]
위 3가지 문자열 클래스는 Java를 사용하면 자주 접하게 되는 문자열 클래스입니다. 이는 모두 문자열을 저장하기도 하고 관리합니다. 하지만, 하는 역할이 비슷하다면 굳이 3가지가 존재해야 할까요? 당연히, 각각의 성능이 다르며 상황에 맞게 사용해야 합니다. 그러므로 하나씩 각 특징과 차이를 알아보겠습니다.
| String vs StringBuffer/StringBuilder
먼저, String의 특징을 살펴보겠습니다.
String과 StringBuffer/StringBuilder의 기본적인 차이는 Immutable(불변) / mutable(가변)입니다. String 객체는 생성이 될 경우, 할당된 메모리 공간에 대한 변화는 일어나지 않습니다. 아래의 코드를 한번 살펴보겠습니다.
public class Main {
public static void main(String[] args) {
String str1 = "Hello";
String str2 = "Hello";
System.out.println(str1 == str2); // true 반환
}
}결과값은 true가 반환됩니다. 위의 str1에서 Hello값을 String Constant Pool에서 검색을 합니다. 만약 없다면 등록하고 해당하는 레퍼런스 값을 반환합니다. str2도 마찬가지로 String Constant Pool에서 검색을 한 후, 이미 등록되어있었기 때문에 같은 레퍼런스 값을 반환하게 되는 것입니다.
또 다른 예시를 보죠!
String str = "Hello World";
str += "!!";
기존에 있던 "Hello World"는 없어지지 않고 새롭게 "Hello World!!"이 Heap 메모리 영역내의 String Constant Pool에 쌓이게 됩니다. 이후, GC(Garbage Collector)가 "Hello World"를 처리해주게 됩니다. 즉, 생성된 객체는 변하지 않고 새로운 객체가 계속 생성되는 것입니다.
그렇다면, StringBuilder와 StringBuffer는 어떨까요?
앞서, String이 불변의 특성을 가지고 있다면 StringBuilder와 StringBuffer는 가변적인 특징을 지니고 있다고 말씀드렸습니다.
StringBuffer sb = new StringBuffer("Hello World");
sb.append("!!");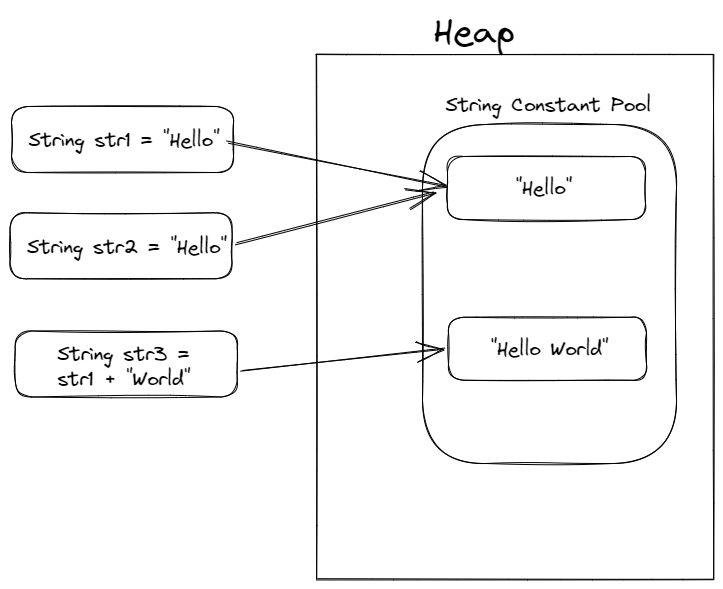
가변적인 특징을 지니고 있기 때문에 처음 생성된 "Hello World"는 append() 메소드를 통해 "Hello World!!"로 변하게 됩니다. 즉, 앞서 확인한 String과는 다르게 새롭게 Heap 영역에 메모리를 쌓지 않고 기존에 있는 객체를 변화시킵니다.
단순히 한 두번의 연산과정일 경우에는 객체가 힙메모리에 쌓이는 것에 대한 우려가 없지만 이러한 예시를 생각해보겠습니다. 이렇게 + 연산과정(추가,삭제,수정)을 1000번하게 되면 String 인스턴스 1000개가 힙메모리에 쌓이게 됩니다. 하지만, StringBuffer나 StringBuilder를 사용하게 되면 하나만 생성하면 되므로 훨씬 효율적이고 힙메모리에 부담이 적을것입니다.
String str = "";
for(int i= 0; i< 1000; i++){
str += i;
}코드도 함께 보겠습니다.
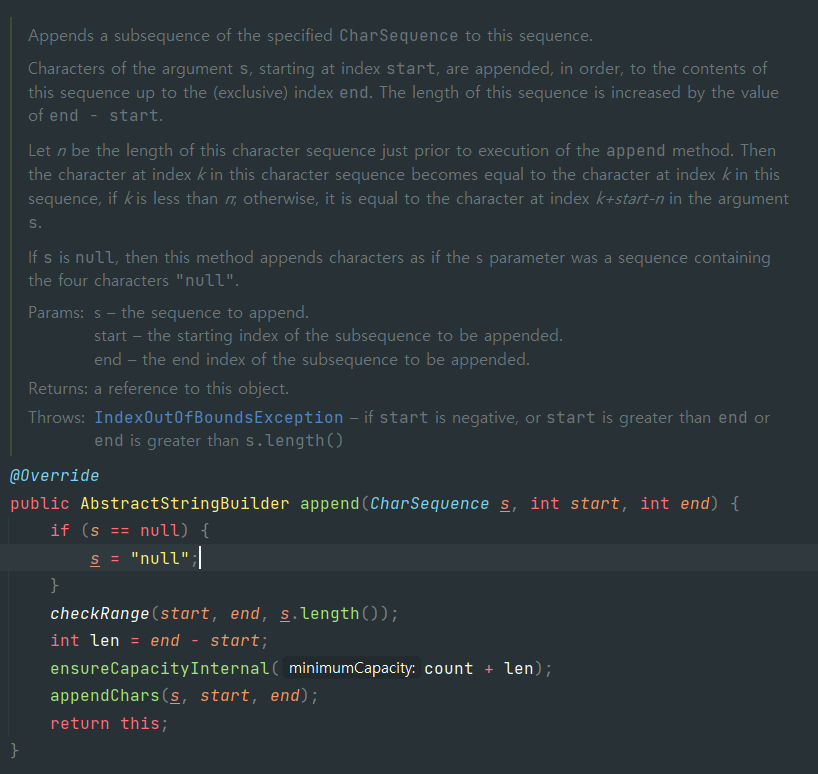

append() 메소드의 설명, 코드에도 나와있듯이, 내부적으로 char[] 배열을 통해 문자의 길이만큼 더합니다. 즉, 가변적으로 문자열을 더할 수 있는 것이죠!AbstractStringBuilder 의 필드에는 byte[]가 선언되어있습니다. Java 9버전 부터 char[]이 byte[]로 선언되어 보다 성능이 향상되었습니다. byte[]는 데이터를 저장하는 저장소 역할을 하며 이 크기를 늘리거나 줄이면서 메소드가 실행됩니다.
| StringBuffer vs StringBuilder
그렇다면, 가변성을 지니고 있는 StringBuffer와 StringBuilder의 차이는 무엇이 있을까요?
가장 큰 차이는 동기화 여부입니다. StringBuffer는 동기화 키워드를 지원하여 멀티쓰레드 환경에서 안전하다는 특징(thread-safe)이 있습니다. 반대로, StringBuilder는 동기화를 지원하지 않기 때문에 멀티쓰레드 환경에서 사용하는 것은 적절하지 않지만, 그렇기 때문에 StringBuilder는 단일쓰레드 환경에서 StringBuffer보다 뛰어난 성능을 지니고 있습니다.
- String은 동기화 키워드를 지원하기 때문에 멀티쓰레드 환경에서 안전하게 사용할 수 있습니다.
* 동기화란?
- 프로세스 혹은 쓰레드들이 수행되는 시점을 조절하여 서로가 알고 있는 정보가 일치하는 것을 의미합니다.
- 보다 쉽게 예시를 들어서 설명해보겠습니다. 만약, A 쓰레드와 B 쓰레드가 하나의 객체에 대해서 작업을 할 때 A가 객체의 값을 변경할 경우, B 쓰레드는 잘못된 값을 이용하여 작업을 할 수 있습니다. 그렇기에 이를 방지하기 위해 데이터의 무결성을 보장하는 것, A 쓰레드와 B 쓰레드가 알고 있는 객체의 정보를 일치시키는 것이 동기화입니다.
(동기화에 대한 공부도 추가적으로 해보겠습니다.)
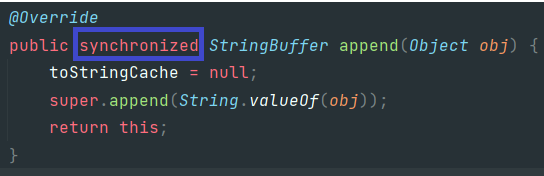

- 사진에 나와있는 것처럼 StringBuffer의 append() 메소드에는 synchronized키워드가 있는 것을, StringBuilder에는 없는 것을 확인할 수 있습니다.
* 간단한 실습 예제
지금까지 공부한 내용을 바탕으로 간단한 멀티쓰레드 예제를 작성해서 확인해보겠습니다.
public class Main {
public static void main(String[] args) throws InterruptedException {
StringBuffer stringBuffer = new StringBuffer();
StringBuilder stringBuilder = new StringBuilder();
Runnable r = new Runnable() {
@Override
public void run() {
for (int i = 0; i < 100; i++) {
String index = String.valueOf(i);
stringBuffer.append("스트링버퍼" + index + " ");
stringBuilder.append("스트링빌더" + index + " ");
}
}
};
// for문을 돌면서 i 값을 StringBuffer와 StringBuilder에 append를 합니다.
// StringBuffer의 append() 메소드는 동기화로 인해 공유되는 자원 변수 i에 대해 쓰레드간의 정보를 알고 있어서 문자열 길이는 언제나 동일합니다.
// StringBuilder의 append() 메소드는 synchronized 코드가 없기 때문에 변수 i에 대한 안전성이 보장되지 않아 문자열 길이는 실행마다 상이합니다.
Thread[] thread = new Thread[100];
// 100개 쓰레드 생성
for (int i = 0; i < thread.length; i++) {
thread[i] = new Thread(r);
thread[i].start();
}
for (int i = 0; i < thread.length; i++) {
thread[i].join();
}
// i 변수 순서대로 thread 종료
System.out.println("멀티 쓰레드 - StringBuffer를 사용했을 때 길이 : " + stringBuffer.length());
System.out.println("멀티 쓰레드 - StringBuilder를 사용했을 때 길이 : " + stringBuilder.length());
// 재차 실행을 해보면 StringBuilder는 결과값이 변하며 StringBuffer의 결과값과 다릅니다.
}
}
- 실행 해보셨으면 값이 차이를 확인하실 수 있습니다. 위에서 확인한 것처럼 StringBuffer는 synchronized 키워드가 있기에 동기화를 지원하여 멀티쓰레드 환경에서 보다 안정성이 있다는 것도 확인 할 수 있습니다.
* 간단한 실습예제 2
String, StringBuilder, StringBuffer간의 성능차이(단일 쓰레드 환경)
public class Performance {
public static long stringRun(int limit) {
long start = System.nanoTime();
String string = "";
for (int i = 0; i < limit; i++)
string += "Java";
long end = System.nanoTime();
return (end - start);
}
public static long stringBufferRun(int limit) {
long start = System.nanoTime();
StringBuffer stringBuffer = new StringBuffer();
for (int i = 0; i < limit; i++)
stringBuffer.append("Java");
long end = System.nanoTime();
return (end - start);
}
public static long stringBuilderRun(int limit) {
long start = System.nanoTime();
StringBuilder stringBuilder = new StringBuilder();
for (int i = 0; i < limit; i++)
stringBuilder.append("Java");
long end = System.nanoTime();
return (end - start);
}
public static void main(String[] args) {
System.out.println("String Performance : " + ((double) stringRun(5000000)) / 1000000000);
System.out.println("StringBuffer Performance : " + ((double) stringBufferRun(5000000)) / 1000000000);
System.out.println("StringBuilder Performance : " + ((double) stringBuilderRun(5000000)) / 1000000000);
}
}- nanoTime() 메소드를 통해 시간을 구했으며 이를 메인 메소드에서 초(second)로 바꿔 출력했습니다.
| limit | String | StringBuffer | StringBuilder |
| 100 | 0.172025 | 0.001069 | 0.0001186 |
| 1000 | 0.0240097 | 0.0002708 | 0.0000941 |
| 10000 | 0.1758702 | 0.0016733 | 0.0017099 |
| 100000 | 8.1529746 | 0.0071732 | 0.0040552 |
| 500000 | 114.9480953 | 0.0111602 | 0.0088464 |
| 1000000 | 511.7338917 | 0.0183034 | 0.0154044 |
| 2500000 | 4050.0690068 | 0.02842 | 0.023767 |
| 5000000 | 17277.8014213 | 0.0454903 | 0.0348172 |
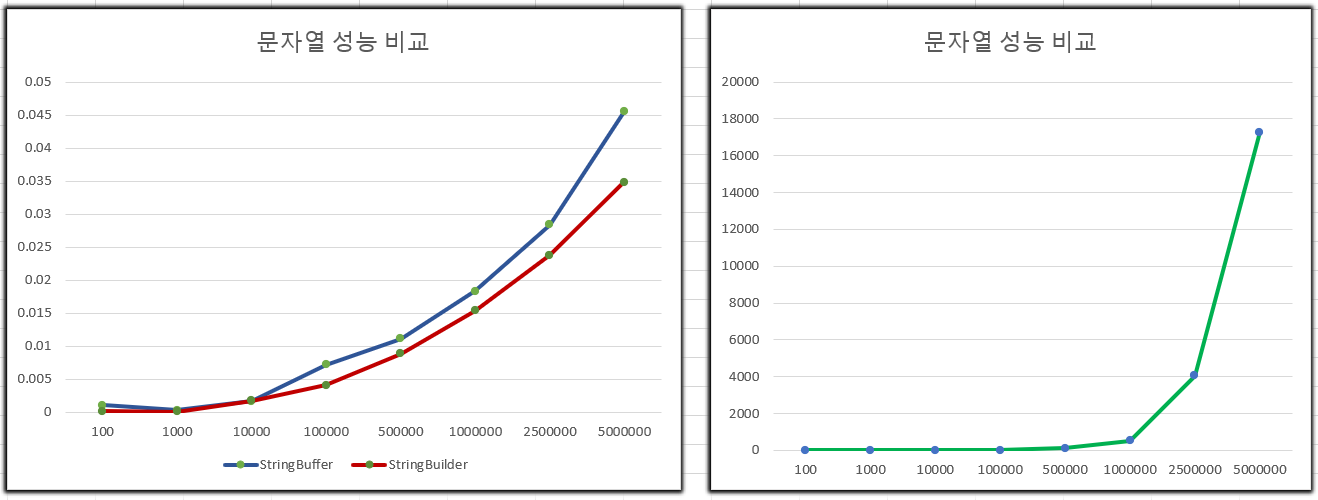
- 500만번의 연산까지한 결과, 단일 쓰레드 환경에서 StingBuilder > StringBuffer > String 순으로 성능이 뛰어난 것을 알 수 있었습니다.
- 함께, 그래프를 표시하고 싶었지만, 시간 차이가 커서 한 눈에 들어오지 않았기에 두 그래프로 나누었습니다.
| Conclusion
각 클래스들을 정리해보겠습니다. 물론, 최적화로 인하여 상이한 성능이 나올 수 있지만, 일반적인 경우에는 아래의 경우를 생각하며 사용하면 됩니다.
| String | StringBuffer | StringBuilder | |
| 연산 과정 | String 인스턴스가 반복적으로 생성 |
하나의 객체를 가변적으로 사용 |
하나의 객체를 가변적으로 사용 |
| 동기화 여부 | O | O | X |
[추가적인 의문]
그렇다면 String은 왜 불변성을 지니도록 만들어진 것일까요?
-> 재사용 가능성이 높을 경우 하나의 String 객체만을 생성하여 JVM의 힙 메모리를 절약함과 동시에 캐싱 기능을 통한 속도 향상에 있습니다.
-> String은 불변성을 지니고 있기 때문에 중요한 데이터를 다룰 경우, 강제로 해당 레퍼런스에 대한 데이터 값을 바꾸는 것을 방지하기 위함입니다. 이는 멀티 쓰레드 환경에서도 불변성의 특징으로 인해 데이터를 안전하게 유지할 수 있습니다.
* JDK 버전 관련
- JDK 1.5 버전 이전일 경우 문자열 연산 이후 만들어진 문자열을 새로운 메모리에 할당하므로 성능상의 이슈가 있습니다.
- JDK 1.5 버전 이후일 경우 컴파일 과정에서 String 객체를 사용하더라도 StringBuilder로 컴파일 되도록 변경되었습니다. 하지만, 언제나 StringBuilder가 사용된다는 보장이없으므로 concatination의 경우에는 StringBuilder 혹은 StringBuffer을 사용해야합니다.
(다만, 반복 루프문을 통해 문자열을 더하는 경우 여전히 객체를 메모리에 추가되는 점은 변경되지 않았습니다. )
(참고한 블로그)
https://ifuwanna.tistory.com/221
https://velog.io/@doghqkr13/String-StringBuilder-StringBuffer
'Develop > JAVA' 카테고리의 다른 글
| Java 디자인 패턴 네번째 이야기 - 팩토리 메소드 패턴(Factory Method Pattern) (0) | 2021.08.16 |
|---|---|
| Java 디자인 패턴 세번째 이야기 - 빌더 패턴(Builder Pattern) (0) | 2021.08.13 |
| Java 디자인 패턴 두번째 이야기 - 프록시 패턴(Proxy Pattern) (0) | 2021.08.10 |
| Java 디자인 패턴 첫번째 이야기 - 싱글톤 패턴(Singleton Pattern) (0) | 2021.08.07 |
| Object 클래스의대표적인 메소드(equals(),hashcode(),toString()) (0) | 2021.08.04 |
[String, StringBuffer 그리고 StringBuilder의 차이를 알아야 하는 이유]
위 3가지 문자열 클래스는 Java를 사용하면 자주 접하게 되는 문자열 클래스입니다. 이는 모두 문자열을 저장하기도 하고 관리합니다. 하지만, 하는 역할이 비슷하다면 굳이 3가지가 존재해야 할까요? 당연히, 각각의 성능이 다르며 상황에 맞게 사용해야 합니다. 그러므로 하나씩 각 특징과 차이를 알아보겠습니다.
| String vs StringBuffer/StringBuilder
먼저, String의 특징을 살펴보겠습니다.
String과 StringBuffer/StringBuilder의 기본적인 차이는 Immutable(불변) / mutable(가변)입니다. String 객체는 생성이 될 경우, 할당된 메모리 공간에 대한 변화는 일어나지 않습니다. 아래의 코드를 한번 살펴보겠습니다.
public class Main {
public static void main(String[] args) {
String str1 = "Hello";
String str2 = "Hello";
System.out.println(str1 == str2); // true 반환
}
}결과값은 true가 반환됩니다. 위의 str1에서 Hello값을 String Constant Pool에서 검색을 합니다. 만약 없다면 등록하고 해당하는 레퍼런스 값을 반환합니다. str2도 마찬가지로 String Constant Pool에서 검색을 한 후, 이미 등록되어있었기 때문에 같은 레퍼런스 값을 반환하게 되는 것입니다.
또 다른 예시를 보죠!
String str = "Hello World";
str += "!!";
기존에 있던 "Hello World"는 없어지지 않고 새롭게 "Hello World!!"이 Heap 메모리 영역내의 String Constant Pool에 쌓이게 됩니다. 이후, GC(Garbage Collector)가 "Hello World"를 처리해주게 됩니다. 즉, 생성된 객체는 변하지 않고 새로운 객체가 계속 생성되는 것입니다.
그렇다면, StringBuilder와 StringBuffer는 어떨까요?
앞서, String이 불변의 특성을 가지고 있다면 StringBuilder와 StringBuffer는 가변적인 특징을 지니고 있다고 말씀드렸습니다.
StringBuffer sb = new StringBuffer("Hello World");
sb.append("!!");
가변적인 특징을 지니고 있기 때문에 처음 생성된 "Hello World"는 append() 메소드를 통해 "Hello World!!"로 변하게 됩니다. 즉, 앞서 확인한 String과는 다르게 새롭게 Heap 영역에 메모리를 쌓지 않고 기존에 있는 객체를 변화시킵니다.
단순히 한 두번의 연산과정일 경우에는 객체가 힙메모리에 쌓이는 것에 대한 우려가 없지만 이러한 예시를 생각해보겠습니다. 이렇게 + 연산과정(추가,삭제,수정)을 1000번하게 되면 String 인스턴스 1000개가 힙메모리에 쌓이게 됩니다. 하지만, StringBuffer나 StringBuilder를 사용하게 되면 하나만 생성하면 되므로 훨씬 효율적이고 힙메모리에 부담이 적을것입니다.
String str = "";
for(int i= 0; i< 1000; i++){
str += i;
}코드도 함께 보겠습니다.
append() 메소드의 설명, 코드에도 나와있듯이, 내부적으로 char[] 배열을 통해 문자의 길이만큼 더합니다. 즉, 가변적으로 문자열을 더할 수 있는 것이죠!AbstractStringBuilder 의 필드에는 byte[]가 선언되어있습니다. Java 9버전 부터 char[]이 byte[]로 선언되어 보다 성능이 향상되었습니다. byte[]는 데이터를 저장하는 저장소 역할을 하며 이 크기를 늘리거나 줄이면서 메소드가 실행됩니다.
| StringBuffer vs StringBuilder
그렇다면, 가변성을 지니고 있는 StringBuffer와 StringBuilder의 차이는 무엇이 있을까요?
가장 큰 차이는 동기화 여부입니다. StringBuffer는 동기화 키워드를 지원하여 멀티쓰레드 환경에서 안전하다는 특징(thread-safe)이 있습니다. 반대로, StringBuilder는 동기화를 지원하지 않기 때문에 멀티쓰레드 환경에서 사용하는 것은 적절하지 않지만, 그렇기 때문에 StringBuilder는 단일쓰레드 환경에서 StringBuffer보다 뛰어난 성능을 지니고 있습니다.
- String은 동기화 키워드를 지원하기 때문에 멀티쓰레드 환경에서 안전하게 사용할 수 있습니다.
* 동기화란?
- 프로세스 혹은 쓰레드들이 수행되는 시점을 조절하여 서로가 알고 있는 정보가 일치하는 것을 의미합니다.
- 보다 쉽게 예시를 들어서 설명해보겠습니다. 만약, A 쓰레드와 B 쓰레드가 하나의 객체에 대해서 작업을 할 때 A가 객체의 값을 변경할 경우, B 쓰레드는 잘못된 값을 이용하여 작업을 할 수 있습니다. 그렇기에 이를 방지하기 위해 데이터의 무결성을 보장하는 것, A 쓰레드와 B 쓰레드가 알고 있는 객체의 정보를 일치시키는 것이 동기화입니다.
(동기화에 대한 공부도 추가적으로 해보겠습니다.)
- 사진에 나와있는 것처럼 StringBuffer의 append() 메소드에는 synchronized키워드가 있는 것을, StringBuilder에는 없는 것을 확인할 수 있습니다.
* 간단한 실습 예제
지금까지 공부한 내용을 바탕으로 간단한 멀티쓰레드 예제를 작성해서 확인해보겠습니다.
public class Main {
public static void main(String[] args) throws InterruptedException {
StringBuffer stringBuffer = new StringBuffer();
StringBuilder stringBuilder = new StringBuilder();
Runnable r = new Runnable() {
@Override
public void run() {
for (int i = 0; i < 100; i++) {
String index = String.valueOf(i);
stringBuffer.append("스트링버퍼" + index + " ");
stringBuilder.append("스트링빌더" + index + " ");
}
}
};
// for문을 돌면서 i 값을 StringBuffer와 StringBuilder에 append를 합니다.
// StringBuffer의 append() 메소드는 동기화로 인해 공유되는 자원 변수 i에 대해 쓰레드간의 정보를 알고 있어서 문자열 길이는 언제나 동일합니다.
// StringBuilder의 append() 메소드는 synchronized 코드가 없기 때문에 변수 i에 대한 안전성이 보장되지 않아 문자열 길이는 실행마다 상이합니다.
Thread[] thread = new Thread[100];
// 100개 쓰레드 생성
for (int i = 0; i < thread.length; i++) {
thread[i] = new Thread(r);
thread[i].start();
}
for (int i = 0; i < thread.length; i++) {
thread[i].join();
}
// i 변수 순서대로 thread 종료
System.out.println("멀티 쓰레드 - StringBuffer를 사용했을 때 길이 : " + stringBuffer.length());
System.out.println("멀티 쓰레드 - StringBuilder를 사용했을 때 길이 : " + stringBuilder.length());
// 재차 실행을 해보면 StringBuilder는 결과값이 변하며 StringBuffer의 결과값과 다릅니다.
}
}
- 실행 해보셨으면 값이 차이를 확인하실 수 있습니다. 위에서 확인한 것처럼 StringBuffer는 synchronized 키워드가 있기에 동기화를 지원하여 멀티쓰레드 환경에서 보다 안정성이 있다는 것도 확인 할 수 있습니다.
* 간단한 실습예제 2
String, StringBuilder, StringBuffer간의 성능차이(단일 쓰레드 환경)
public class Performance {
public static long stringRun(int limit) {
long start = System.nanoTime();
String string = "";
for (int i = 0; i < limit; i++)
string += "Java";
long end = System.nanoTime();
return (end - start);
}
public static long stringBufferRun(int limit) {
long start = System.nanoTime();
StringBuffer stringBuffer = new StringBuffer();
for (int i = 0; i < limit; i++)
stringBuffer.append("Java");
long end = System.nanoTime();
return (end - start);
}
public static long stringBuilderRun(int limit) {
long start = System.nanoTime();
StringBuilder stringBuilder = new StringBuilder();
for (int i = 0; i < limit; i++)
stringBuilder.append("Java");
long end = System.nanoTime();
return (end - start);
}
public static void main(String[] args) {
System.out.println("String Performance : " + ((double) stringRun(5000000)) / 1000000000);
System.out.println("StringBuffer Performance : " + ((double) stringBufferRun(5000000)) / 1000000000);
System.out.println("StringBuilder Performance : " + ((double) stringBuilderRun(5000000)) / 1000000000);
}
}- nanoTime() 메소드를 통해 시간을 구했으며 이를 메인 메소드에서 초(second)로 바꿔 출력했습니다.
| limit | String | StringBuffer | StringBuilder |
| 100 | 0.172025 | 0.001069 | 0.0001186 |
| 1000 | 0.0240097 | 0.0002708 | 0.0000941 |
| 10000 | 0.1758702 | 0.0016733 | 0.0017099 |
| 100000 | 8.1529746 | 0.0071732 | 0.0040552 |
| 500000 | 114.9480953 | 0.0111602 | 0.0088464 |
| 1000000 | 511.7338917 | 0.0183034 | 0.0154044 |
| 2500000 | 4050.0690068 | 0.02842 | 0.023767 |
| 5000000 | 17277.8014213 | 0.0454903 | 0.0348172 |
- 500만번의 연산까지한 결과, 단일 쓰레드 환경에서 StingBuilder > StringBuffer > String 순으로 성능이 뛰어난 것을 알 수 있었습니다.
- 함께, 그래프를 표시하고 싶었지만, 시간 차이가 커서 한 눈에 들어오지 않았기에 두 그래프로 나누었습니다.
| Conclusion
각 클래스들을 정리해보겠습니다. 물론, 최적화로 인하여 상이한 성능이 나올 수 있지만, 일반적인 경우에는 아래의 경우를 생각하며 사용하면 됩니다.
| String | StringBuffer | StringBuilder | |
| 연산 과정 | String 인스턴스가 반복적으로 생성 |
하나의 객체를 가변적으로 사용 |
하나의 객체를 가변적으로 사용 |
| 동기화 여부 | O | O | X |
[추가적인 의문]
그렇다면 String은 왜 불변성을 지니도록 만들어진 것일까요?
-> 재사용 가능성이 높을 경우 하나의 String 객체만을 생성하여 JVM의 힙 메모리를 절약함과 동시에 캐싱 기능을 통한 속도 향상에 있습니다.
-> String은 불변성을 지니고 있기 때문에 중요한 데이터를 다룰 경우, 강제로 해당 레퍼런스에 대한 데이터 값을 바꾸는 것을 방지하기 위함입니다. 이는 멀티 쓰레드 환경에서도 불변성의 특징으로 인해 데이터를 안전하게 유지할 수 있습니다.
* JDK 버전 관련
- JDK 1.5 버전 이전일 경우 문자열 연산 이후 만들어진 문자열을 새로운 메모리에 할당하므로 성능상의 이슈가 있습니다.
- JDK 1.5 버전 이후일 경우 컴파일 과정에서 String 객체를 사용하더라도 StringBuilder로 컴파일 되도록 변경되었습니다. 하지만, 언제나 StringBuilder가 사용된다는 보장이없으므로 concatination의 경우에는 StringBuilder 혹은 StringBuffer을 사용해야합니다.
(다만, 반복 루프문을 통해 문자열을 더하는 경우 여전히 객체를 메모리에 추가되는 점은 변경되지 않았습니다. )
(참고한 블로그)
https://ifuwanna.tistory.com/221
https://velog.io/@doghqkr13/String-StringBuilder-StringBuffer
'Develop > JAVA' 카테고리의 다른 글
| Java 디자인 패턴 네번째 이야기 - 팩토리 메소드 패턴(Factory Method Pattern) (0) | 2021.08.16 |
|---|---|
| Java 디자인 패턴 세번째 이야기 - 빌더 패턴(Builder Pattern) (0) | 2021.08.13 |
| Java 디자인 패턴 두번째 이야기 - 프록시 패턴(Proxy Pattern) (0) | 2021.08.10 |
| Java 디자인 패턴 첫번째 이야기 - 싱글톤 패턴(Singleton Pattern) (0) | 2021.08.07 |
| Object 클래스의대표적인 메소드(equals(),hashcode(),toString()) (0) | 2021.08.04 |